

推荐系统作为一种智能化的信息过滤技术,已在实际场景中得到广泛的应用。然而,推荐系统的成功往往建立在大量的用户数据之上,而这些数据可能涉及用户的私密和敏感信息。在用户信息受到隐私保护限制或无法获取的场景下,传统的推荐系统往往难以发挥良好的效果。因此,如何在保证隐私安全性的前提下,构建可信赖的推荐系统,是一个亟待解决的问题。
近年来,随着用户对自身隐私的重视程度不断提高,越来越多的用户倾向于在使用在线平台时不进行登录操作,这也使得匿名的基于会话的推荐成为一个重要的研究方向。近日,来自香港科技大学、北京大学、微软亚研等机构的研究者提出了一种高效利用多级用户意图的新模型 Atten-Mixer。研究论文获得 WSDM2023 最佳论文荣誉提名。


论文链接:https://dl.acm.org/doi/abs/10.1145/3539597.3570445
研究背景
基于会话的推荐 (Session-based recommendation, SBR) 是一种基于用户在短暂、动态的会话(即用户的行为序列)进行推荐的方法。
与传统的基于用户或物品的推荐系统相比,SBR 更侧重于捕捉用户在当前会话中的即时需求,能够更有效地适应用户兴趣的快速演化和长尾效应的挑战。
在 SBR 模型的演进过程中,从基于循环神经网络 (Recurrent Neural Network, RNN) 的模型,到基于卷积神经网络 (Convolutional Neural Network, CNN) 的模型,再到近期的 SBR 研究中广泛采用基于图神经网络 (Graph Neural Network, GNN) 的模型来更好地挖掘物品之间复杂的转移关系。
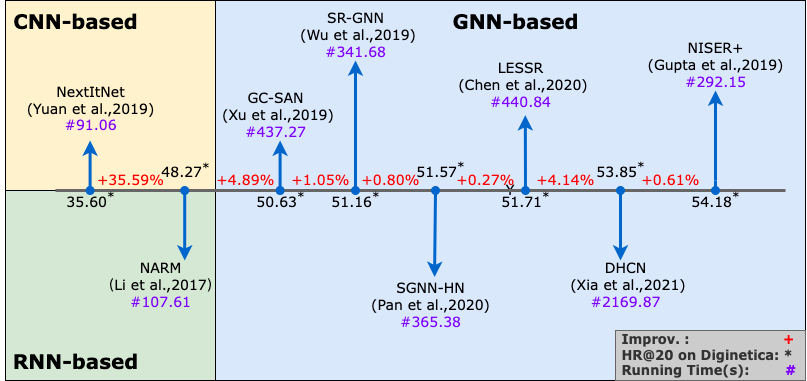
然而,这些模型在基准数据集上的性能提升与其模型复杂度的指数级增长相比显得十分有限。面对这种现象,本文提出了如下问题:这些基于 GNN 的模型是不是对于 SBR 来说过于简单或者过于复杂了?
初步分析
为了回答这个问题,作者试图解构现有的基于 GNN 的 SBR 模型,并分析它们在 SBR 任务上的作用。
一般来说,典型的基于 GNN 的 SBR 模型可以分解为两个部分:
(1)GNN 模块。参数可以分为图卷积的传播权重和将原始嵌入和图卷积输出融合的 GRU 权重。
(2)Readout 模块。参数包括用于生成长期表示的注意力池化权重和用于生成会话表示以进行预测的转换权重。

接下来,作者分别在这两个部分上采用 Sparse Variational Dropout(SparseVD),一种常用的神经网络稀疏化技术,并在训练模型时计算参数的密度比 (density ratio)。
参数的 density ratio 指的是参数的权重中大于某个阈值的元素数与总元素数的比例,其数值可用于衡量参数的重要性。
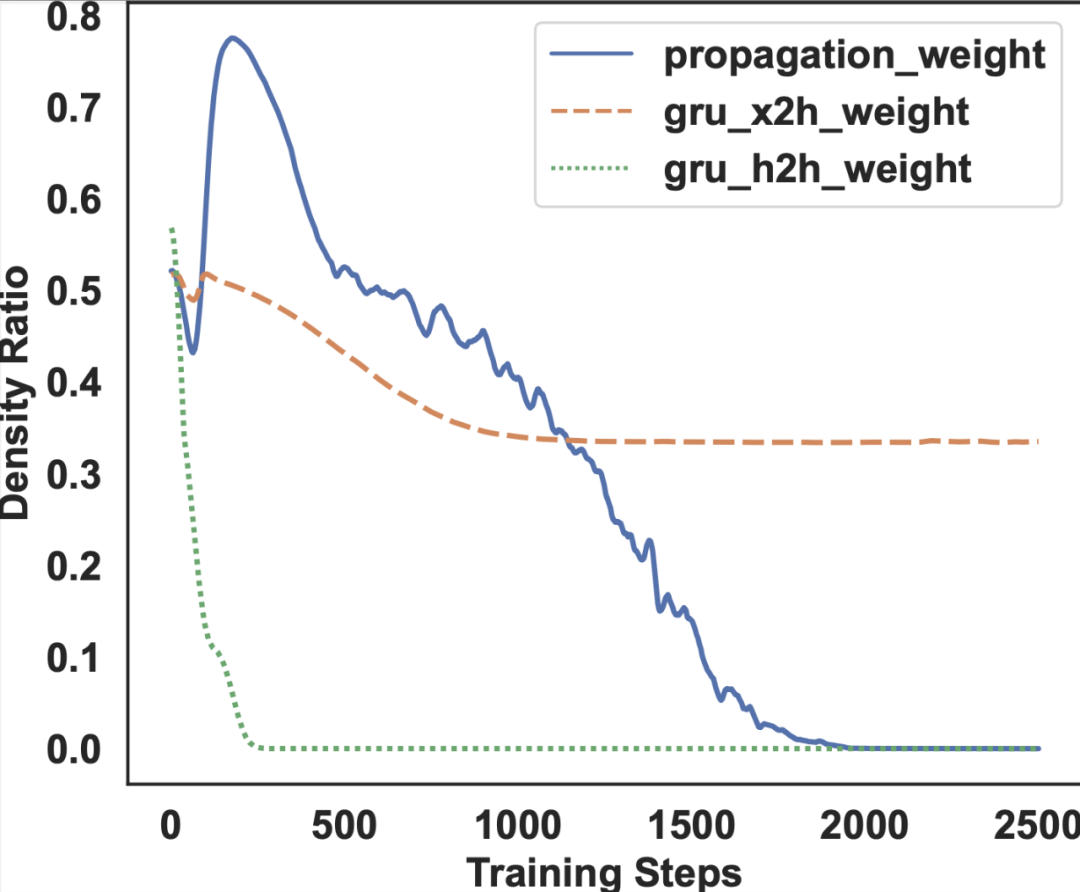
GNN 模块。
由于 GNN 有很多参数,随着随机初始化,在一开始会有许多要更新的知识。因此我们可以看到图卷积传播权重的 density ratio 在一开始的几个 batch 数据上会有波动。随着训练趋于稳定,该 density ratio 会趋于 0。
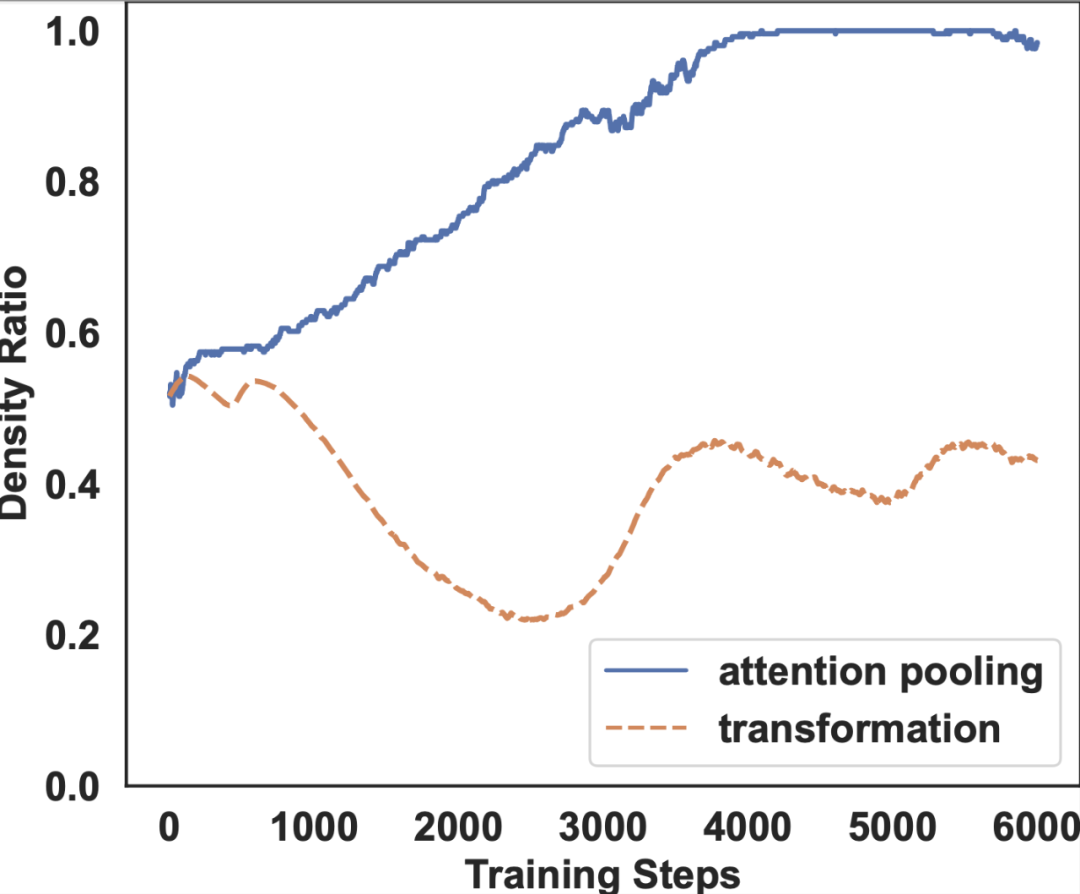
Readout 模块。
我们可以发现,随着训练的进行,注意力池化权重的 density ratio 可以保持在一个较高水平。在其他数据集和其他 GNN-based SBR 模型上,我们也可以观测到相同的趋势。
因此,作者发现 GNN 模块的许多参数在训练过程中都是冗余的。 基于此,作者提出了以下用于 SBR 的更简单而更有效的模型设计准则:
(1) 不过分追求复杂的 GNN 设计,作者倾向于删除 GNN 传播部分,仅保留初始嵌入层;
(2) 模型设计者应该更加关注基于注意力的 Readout 模块。
由于注意力池化权重参数保持了较高的密度比,作者推测在基于注意力的 readout 方法上进行更先进的架构设计将会更有利。
由于本文放弃了对 GNN 传播部分的依赖,Readout 模块应该承担更多模型推理上的责任。
考虑到现有的基于实例视图 (instance-view) 的 Readout 模块的推理能力有限,本文需要设计具有更强的推理能力的 Readout 模块。
如何设计具有更强推理能力的 Readout 模块
根据精神病理学的研究,人类推理本质上是一种多层次信息处理的过程。
例如,通过综合考虑 Alice 交互的底层商品,人类可以获得一些更高层次的概念,比如 Alice 是否打算筹备婚礼或者装饰新房子。在确定 Alice 很可能是在筹备婚礼后,人类接着会考虑与花束相关的婚礼用品,如婚礼气球,而不是与花束相关的装饰用品,如壁画。
在推荐系统中采用这种多层次推理策略可以帮助剪枝大量的搜索空间,避免局部最优解,通过考虑用户的整体行为趋势,收敛到更令人满意的解决方案。
因此,本文希望在 Readout 模块设计中引入这种多层推理的机制。
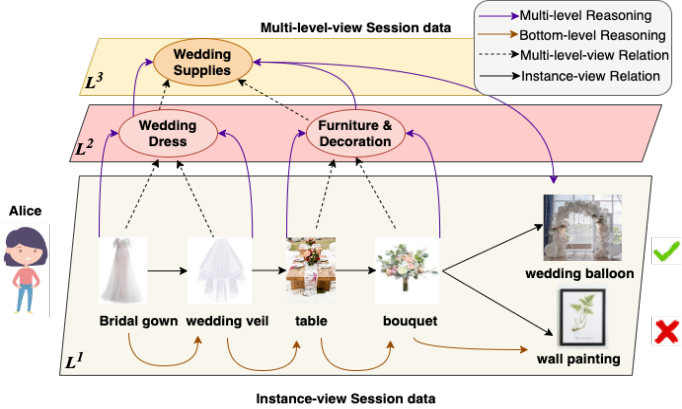
然而,获得这些高层概念不是一件容易事,因为单纯地枚举这些高层概念并不现实,并且很可能引入无关的概念并干扰模型的性能。
为了应对这个挑战,本文采用两个 SBR 相关的归纳偏置 (inductive biases): 即局部不变性 (local invariance) 和固有优先级 (inherent priority),来缩减搜索空间。
- 固有优先级指的是 session 中后几个 item 更能反映用户的当前兴趣;
- 局部不变性指的是 session 中后几个 item 的相对顺序并不影响用户的兴趣,因此在实践中可以通过不同数目的尾部 item 形成 group,通过这些 group 来构建相关的高层概念。
在这里尾部 item 对应固有优先级,group 对应局部不变性,而不同数目则代表本文考虑多层的高层概念。
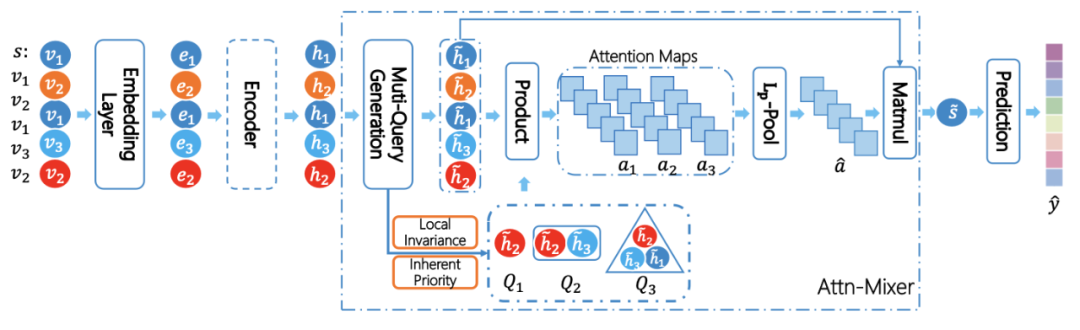
提出模型
因此,本文提出了一个名为 Atten-Mixer 的模型。该模型可以与各种编码器集成。对于输入 session,模型从 embedding 层中获取每个 item 的 embedding。然后,模型对生成的 group representation 应用 linear transformation,以生成多级用户意图查询(multi-level user intent queries)。
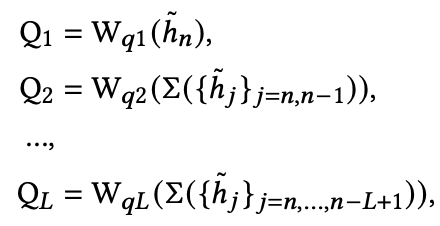
其中 Q1 是 instance-view attention query,而其他的则是更高级别的 attention query,具有不同的感受野和局部不变信息。接下来,模型使用生成的 attention queries 来 attend 该 session 中每个 item 的 hidden state,并获得最终的 session representation。
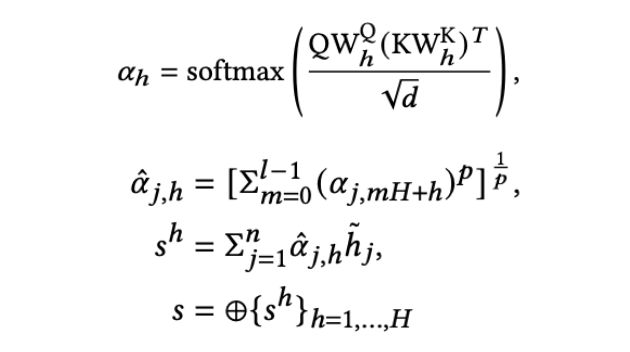
实验及结果
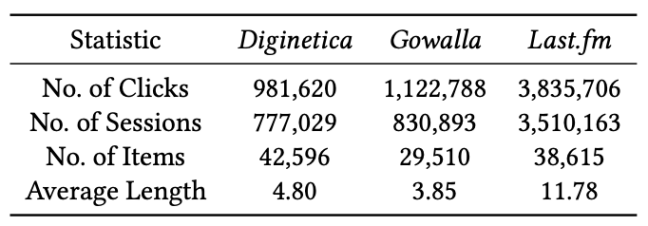
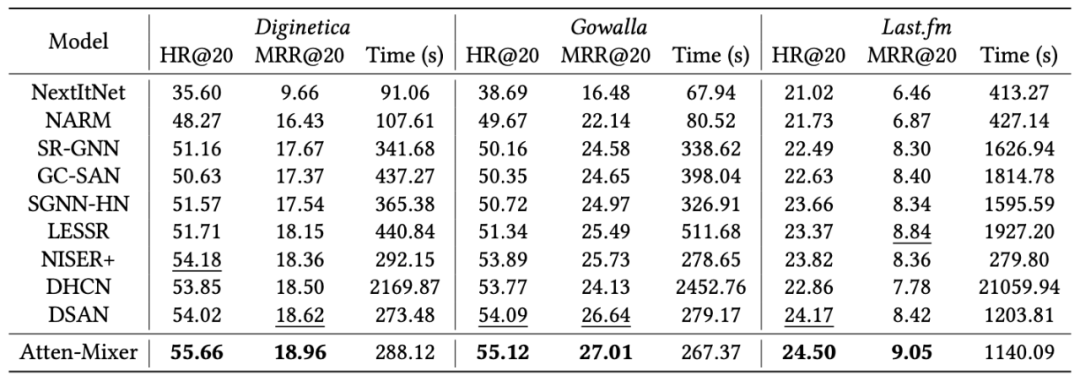
在离线实验中,本文采用了三个不同领域的数据集:Diginetica 是电子商务交易的数据集,Gowalla 是社交网络的数据集,Last.fm 是音乐推荐的数据集。
离线实验结果
(1) 整体对比
作者将 Atten-Mixer 与基于 CNN、基于 RNN、基于 GNN 和基于 readout 的四种基准方法进行了对比。
实验结果表明,Atten-Mixer 在三个数据集上都在准确性和效率方面超越了基准方法。
(2) 性能提升分析
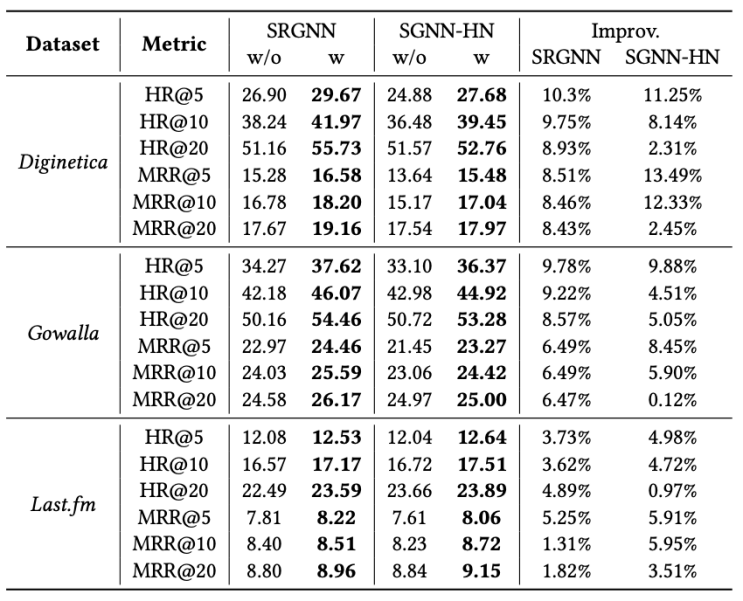
此外,作者还将 Atten-Mixer 模块嵌入到 SR-GNN 和 SGNN-HN 中,以验证该方法对原始模型的性能提升作用。
离线实验结果显示,Atten-Mixer 在所有数据集上都显著提升了模型性能,尤其是在评价指标中的 K 值较小时,说明 Atten-Mixer 能够帮助原始模型生成更精确和用户友好的推荐。
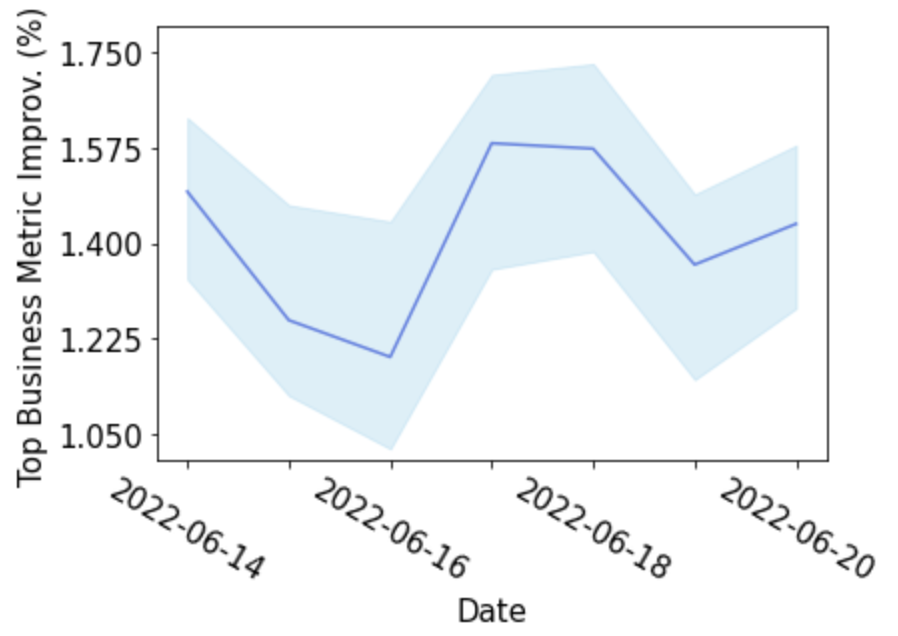
在线实验结果
作者还于 2021 年 4 月将 Atten-Mixer 部署到了大规模电商在线服务中,线上实验显示多级注意力混合网络 (Atten-Mixer) 在各种线上业务指标上都取得了显著提升。
实验结论
总结一下,Atten-Mixer 具备多级推理能力,在准确性和效率方面展现了优异的在线和离线性能。以下是一些主要贡献:
- 复杂的模型架构并不是 SBR 的必要条件,而基于注意力的 readout 方法的创新架构设计则是一种有效的解决方案。
- 多级概念相关性有助于捕捉用户的兴趣,利用归纳偏差是发现信息丰富的高阶概念的有效途径。
研究过程
最后,值得一提的是,这篇文章在获得 WSDM2023 最佳论文荣誉提名的背后还有一段曲折的开发经历,如文章作者之一来自 UIUC 的 Haohan Wang 介绍的那样,这篇文章其实先后因为太过简单而在投稿过程中拒绝过多次,值得庆幸的是,文章的作者并没有为了中文章而去迎合审稿人的口味,而是坚持了自己简单的方法,并最终让这篇文章获得了荣誉。

文章版权声明
1 原创文章作者:红伞伞躺板板,如若转载,请注明出处: https://www.52hwl.com/71158.html
2 温馨提示:软件侵权请联系469472785#qq.com(三天内删除相关链接)资源失效请留言反馈
3 下载提示:如遇蓝奏云无法访问,请修改lanzous(把s修改成x)
4 免责声明:本站为个人博客,所有软件信息均来自网络 修改版软件,加群广告提示为修改者自留,非本站信息,注意鉴别
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫