
多模态学习旨在理解和分析来自多种模态的信息,近年来在监督机制方面取得了实质性进展。
然而,对数据的严重依赖加上昂贵的人工标注阻碍了模型的扩展。与此同时,考虑到现实世界中大规模的未标注数据的可用性,自监督学习已经成为缓解标注瓶颈的一种有吸引力的策略。
基于这两个方向,自监督多模态学习(SSML)提供了从原始多模态数据中利用监督的方法。


论文地址:https://arxiv.org/abs/2304.01008
项目地址:https://github.com/ys-zong/awesome-self-supervised-multimodal-learning
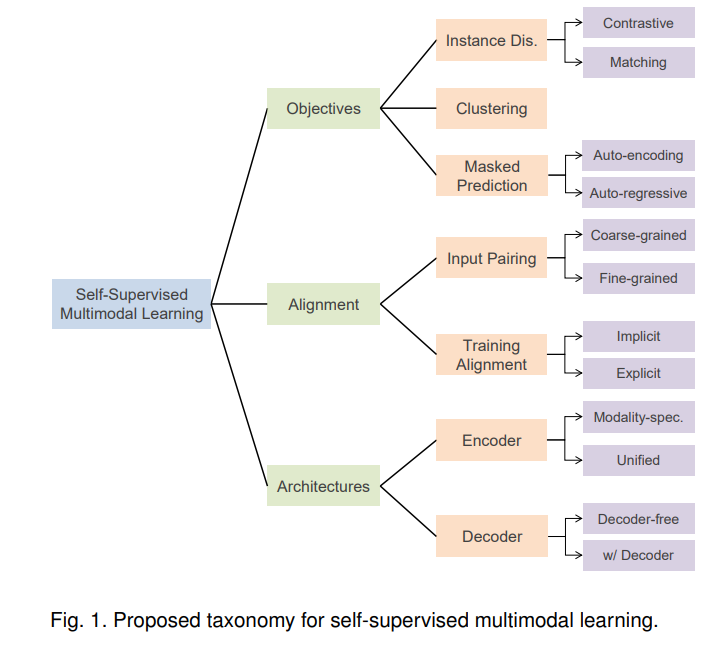
在本综述中,我们对SSML的最先进技术进行了全面的回顾,我们沿着三个正交的轴进行分类: 目标函数、数据对齐和模型架构。这些坐标轴对应于自监督学习方法和多模态数据的固有特征。
具体来说,我们将训练目标分为实例判别、聚类和掩码预测类别。我们还讨论了训练期间的多模态输入数据配对和对齐策略。最后,回顾了模型架构,包括编码器、融合模块和解码器的设计,这些是SSML方法的重要组成部分。
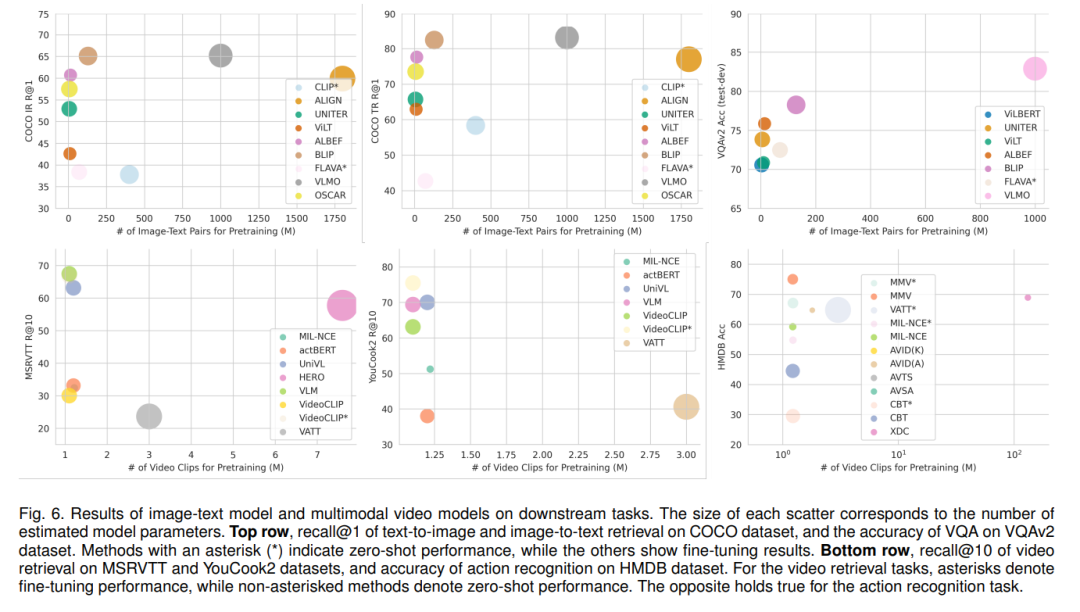
回顾了下游的多模态应用任务,报告了最先进的图像-文本模型和多模态视频模型的具体性能,还回顾了SSML算法在不同领域的实际应用,如医疗保健、遥感和机器翻译。最后,讨论了SSML面临的挑战和未来的方向。
1. 引言
人类通过各种感官感知世界,包括视觉、听觉、触觉和嗅觉。我们通过利用每个模态的互补信息来全面了解我们的周围环境。AI研究一直致力于开发模仿人类行为并以类似方式理解世界的智能体。为此,多模态机器学习领域[1]、[2]旨在开发能够处理和整合来自多个不同模态的数据的模型。近年来,多模态学习取得了重大进展,导致了视觉和语言学习[3]、视频理解[4]、[5]、生物医学[6]、自动驾驶[7]等领域的一系列应用。更根本的是,多模态学习正在推进人工智能中长期存在的接地问题[8],使我们更接近更一般的人工智能。
然而,多模态算法往往仍然需要昂贵的人工标注才能进行有效的训练,这阻碍了它们的扩展。最近,自监督学习(SSL)[9],[10]已经开始通过从现成的标注数据中生成监督来缓解这一问题。单模态学习中自监督的定义相当完善,仅取决于训练目标,以及是否利用人工标注进行监督。然而,在多模态学习的背景下,它的定义则更为微妙。在多模态学习中,一种模态经常充当另一种模态的监督信号。就消除人工标注瓶颈进行向上扩展的目标而言,定义自我监督范围的关键问题是跨模态配对是否自由获取。
通过利用免费可用的多模态数据和自监督目标,自监督多模态学习(SSML)显著增强了多模态模型的能力。在本综述中,我们回顾了SSML算法及其应用。我们沿着三个正交的轴分解各种方法:目标函数、数据对齐和模型架构。这些坐标轴对应于自监督学习算法的特点和多模态数据所需的具体考虑。图1提供了拟议分类法的概述。基于前置任务,我们将训练目标分为实例判别、聚类和掩码预测类别。还讨论了将这些方法中的两种或两种以上结合起来的混合方法。
多模态自监督所特有的是多模态数据配对的问题。模态之间的配对,或者更一般的对齐,可以被SSML算法利用作为输入(例如,当使用一种模态为另一种模态提供监督时),但也可以作为输出(例如,从未配对的数据中学习并将配对作为副产品诱导)。我们讨论了对齐在粗粒度上的不同作用,这种粗粒度通常被假定在多模态自监督中免费可用(例如,网络爬取的图像和标题[11]);有时由SSML算法显式或隐式诱导的细粒度对齐(例如,标题词和图像块[12]之间的对应关系)。此外,我们探索了目标函数和数据对齐假设的交集。
还分析了当代SSML模型架构的设计。具体来说,我们考虑编码器和融合模块的设计空间,将特定模式的编码器(没有融合或具有后期融合)和具有早期融合的统一编码器进行对比。我们也检查具有特定解码器设计的架构,并讨论这些设计选择的影响。
最后,讨论了这些算法在多个真实世界领域的应用,包括医疗保健、遥感、机器翻译等,并对SSML的技术挑战和社会影响进行了深入讨论,指出了潜在的未来研究方向。我们总结了在方法、数据集和实现方面的最新进展,为该领域的研究人员和从业人员提供一个起点。
现有的综述论文要么只关注有监督的多模态学习[1],[2],[13],[14],或单模态自监督学习[9],[10],[15],或SSML的某个子区域,例如视觉-语言预训练[16]。最相关的综述是[17],但它更侧重于时间数据,忽略了对齐和架构的多模态自监督的关键考虑因素。相比之下,我们提供了一个全面和最新的SSML算法综述,并提供了一个涵盖算法、数据和架构的新分类法。
2. 背景知识
多模态学习中的自监督
我们首先描述了本次调研中所考虑的SSML的范围,因为这个术语在之前的文献中使用不一致。通过调用不同借口任务的无标签性质,在单模态环境中定义自监督更为直接,例如,著名的实例辨别[20]或掩盖预测目标[21]实现了自监督。相比之下,多模态学习中的情况更加复杂,因为模态和标签的作用变得模糊。例如,在监督图像字幕[22]中,文本通常被视为标签,但在自监督多模态视觉和语言表示学习[11]中,文本则被视为输入模态。
在多模态环境中,术语自监督已被用于指至少四种情况:(1)从自动成对的多模态数据中进行无标签学习——例如带有视频和音频轨道的电影[23],或来自RGBD摄像机[24]的图像和深度数据。(2)从多模态数据中学习,其中一个模态已经被手动标注,或者两个模态已经被手动配对,但这个标注已经为不同的目的创建,因此可以被认为是免费的,用于SSML预训练。例如,从网络爬取的匹配图像-标题对,如开创性的CLIP[11]所使用的,实际上是监督度量学习[25],[26]的一个例子,其中配对是监督。然而,由于模式和配对都是大规模免费提供的,因此它通常被描述为自监督的。这种未经策划的偶然创建的数据通常比专门策划的数据集(如COCO[22]和Visual Genome[27])质量更低,噪音更大。(3)从高质量的目的标注的多模态数据(例如,COCO[22]中的手动字幕图像)中学习,但具有自监督的风格目标,例如Pixel-BERT[28]。(4)最后,还有一些“自监督”方法,它们混合使用免费和手动标注的多模态数据[29],[30]。为了本次调查的目的,我们遵循自监督的思想,旨在通过打破手动标注的瓶颈来扩大规模。因此,就能够在免费可用的数据上进行训练而言,我们包括了前面两类和第四类方法。我们排除了仅显示用于手动管理数据集的方法,因为它们在管理数据集上应用典型的“自监督”目标(例如,屏蔽预测)。
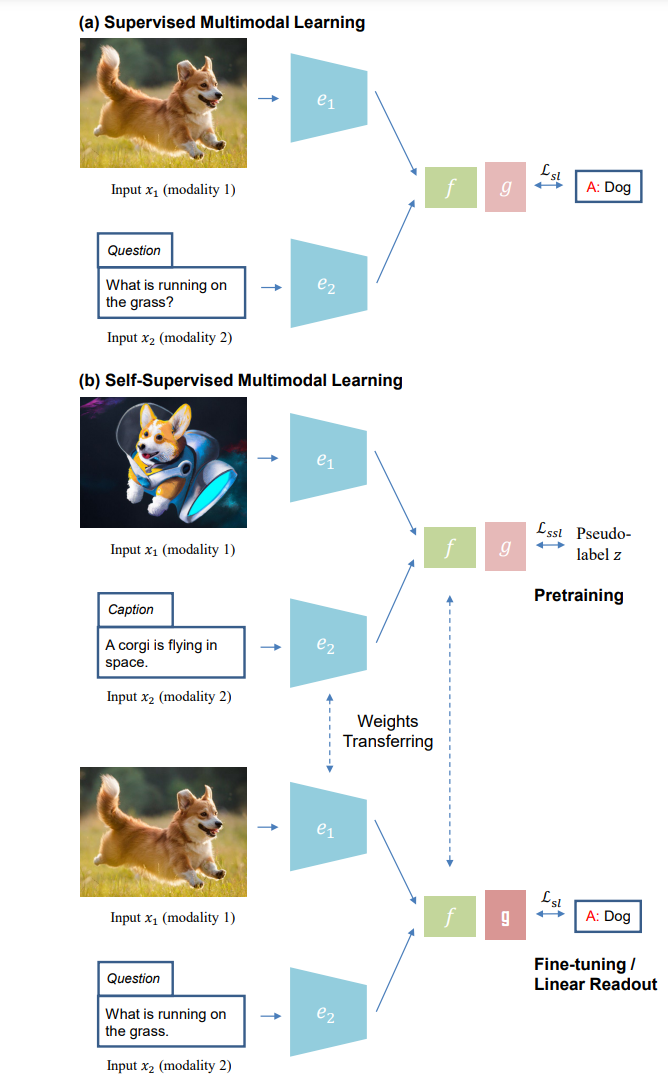
(a)监督式多模态学习和(b)自监督式多模态学习的学习范式:无手动标注的自监督预训练(上);对下游任务进行监督微调(下)。
3. 目标函数
在本节中,我们将介绍用于训练三类自监督多模态算法的目标函数:实例判别、聚类和掩盖预测。最后我们还讨论了混合目标。
3.1 实例判别
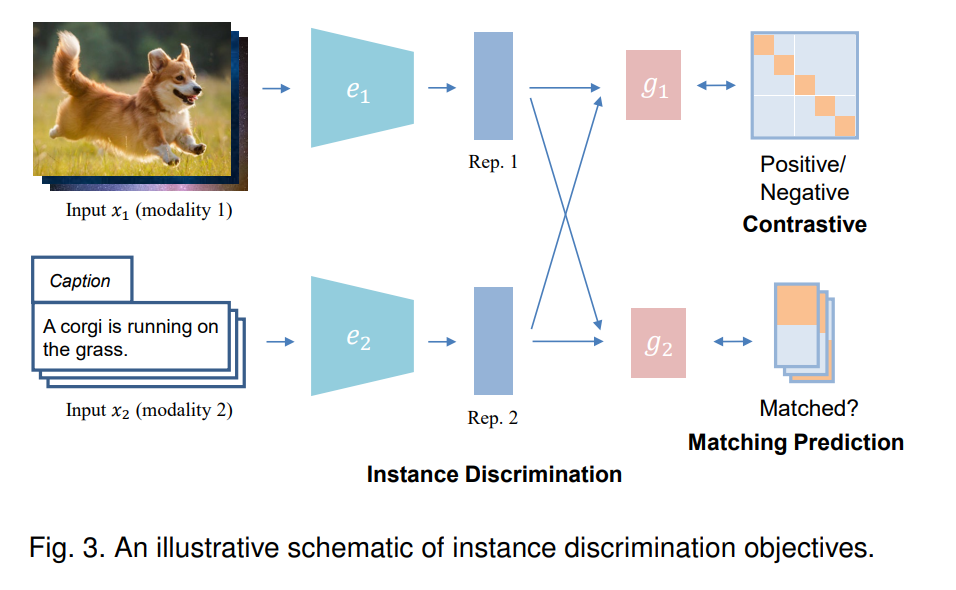
在单模学习中,实例判别(instance discrimination, ID)将原始数据中的每个实例视为一个单独的类,并对模型进行训练,以区分不同的实例。在多模态学习的背景下,实例判别通常旨在确定来自两个输入模态的样本是否来自同一个实例,即配对。通过这样做,它试图对齐成对模式的表示空间,同时将不同实例对的表示空间推得更远。有两种类型的实例识别目标:对比预测和匹配预测,这取决于输入是如何采样的。
3.2 聚类
聚类方法假设应用经过训练的端到端聚类将导致根据语义显著特征对数据进行分组。在实践中,这些方法迭代地预测编码表示的聚类分配,并使用这些预测(也称为伪标签)作为监督信号来更新特征表示。多模态聚类提供了学习多模态表示的机会,还通过使用每个模态的伪标签监督其他模态来改进传统聚类。
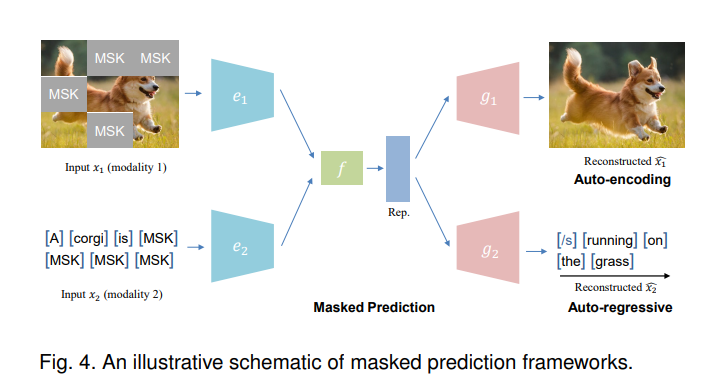
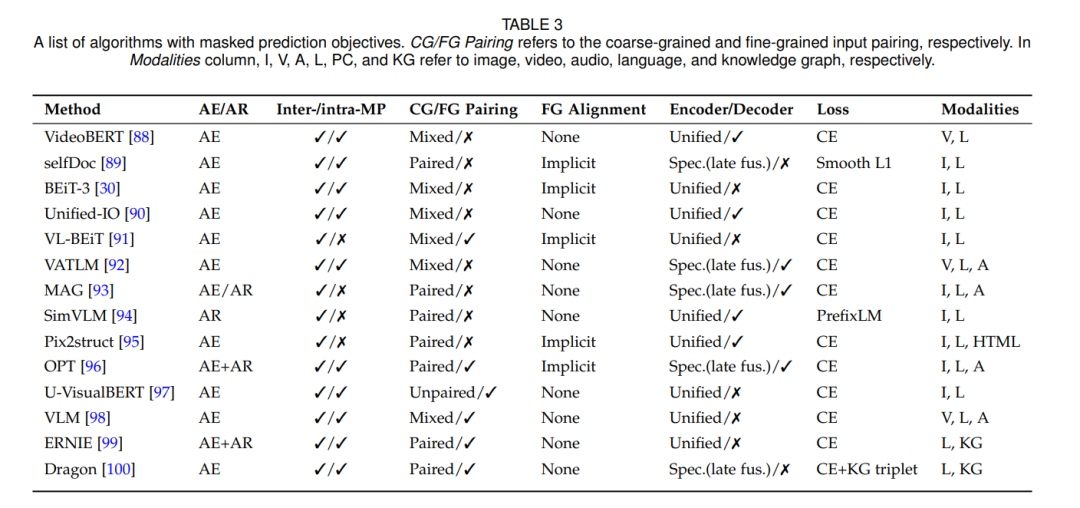
3.3 掩码预测
掩码预测任务可以采用自动编码(类似于BERT[101])或自动回归方法(类似于GPT[102])来执行。
文章版权声明
1 原创文章作者:唐宋元明清,如若转载,请注明出处: https://www.52hwl.com/71153.html
2 温馨提示:软件侵权请联系469472785#qq.com(三天内删除相关链接)资源失效请留言反馈
3 下载提示:如遇蓝奏云无法访问,请修改lanzous(把s修改成x)
4 免责声明:本站为个人博客,所有软件信息均来自网络 修改版软件,加群广告提示为修改者自留,非本站信息,注意鉴别
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫