
自微软3月初发布多模态模型 Kosmos-1 以来,一直在测试和调整 OpenAI 的多模态模型,并将其更好地兼容微软自有产品。
果不其然,趁着GPT-4发布之际,微软也正式摊牌,New Bing早就已经用上GPT-4了。


ChatGPT用的语言模型是 GPT-3.5,在谈到GPT-4比前一个版本强大在哪里时,OpenAI称,虽然这两个版本在随意的谈话中看起来很相似,但「当任务的复杂性达到足够的阈值时,差异就会出现」,GPT-4更可靠、更有创意,并且能够处理更细微的指令。
王者加冕?关于GPT-4的八点观察
1. 再度惊艳,强过人类
如果说GPT-3系列模型向大家证明了AI能够在一个模型里做多个任务,指明实现AGI的路径,GPT-4在很多任务上已经达到人类水平(human-level),甚至比人类表现更好。GPT-4在很多专业的学术考试上已经超越90%的人类,比如在模拟律师考试中,分数在应试者的前10%左右。对此,各类中小学、大学和专业教育该如何应对?
2. 「科学」炼丹
虽然OpenAI此次并未公布具体参数,但可以猜到GPT-4模型一定不小,模型太多就意味着高额训练成本。与此同时,训练模型也很像「炼丹」,需要做很多实验,如果这些实验都是在真实环境下去训练,高昂成本压力不是谁都能承受的。
为此,OpenAI别出心裁搞了一个所谓的「predictable scaling」,简言之就是用万分之一的成本来预测各个实验的结果(loss和human eval)。如此一来,就把原本大模型「碰运气」的炼丹训练升级为「半科学」的炼丹。
3. 众包评测,一举双得
这次非常「取巧」地提供了一个open source的OpenAI Evals,用众包方式开放给各位开发者或爱好者,邀请大家使用Evals来测试模型,同时笼络开发者生态。这一方式,既让大家有参与感,又能让大家免费帮忙评估提高系统,OpenAI直接获得问题和反馈,一石二鸟。

4. 工程补漏
这次还发布了一个System Card,是一个开放的「打补丁」工具,可以发现漏洞减少语言模型的「胡说八道」问题。系统打了各种各样的补丁做预处理和后处理,后面还会开放代码把打补丁能力众包给大家,OpenAI未来也许可以让大家帮它一起做。这标志着LLM终于从一个优雅简单的next token prediction任务进入了各种messy的工程hack了。
5. 多模态
自上周德国微软透露GPT-4是多模态后,大众可谓万众期待。
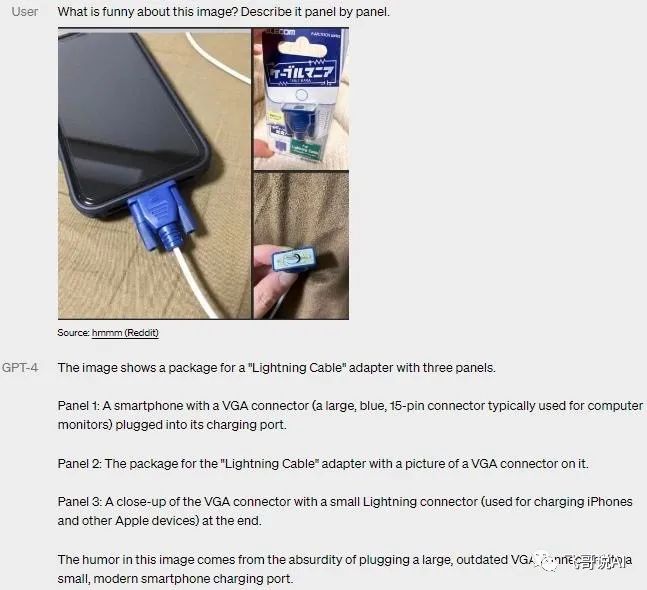
GPT-4千呼万唤始出来,被誉为「堪比人脑」的多模态其实跟目前很多论文阐述的多模态能力并无太多差别,主要区别就是把文本模型的few-shot和逻辑链(COT)结合进来,这里有个前提是需要一个基础能力很好的文本LLM再加多模态,会产生不错的效果。
6. 有计划地放出「王炸」
按照OpenAI演示GPT-4的demo视频里的说法,GPT-4 早在去年8月就已完成训练,但今天才发布,剩下的时间都在进行大量测试和各种查漏补缺,以及最重要的去除危险内容生成的工作。
当大家还沉浸在ChatGPT惊人的生成能力之时,OpenAI已经搞定GPT-4,这波谷歌工程师估计又要熬夜追赶了?
7. OpenAI不再Open
OpenAI在公开的论文里完全没有提及任何模型参数和数据规模(网传GPT-4参数已达100万亿),也没有任何技术原理,对此解释说是为了普惠大众,怕大家学会了怎么做GPT-4之后会用来做恶,触发一些不可控的事情发生,个人完全不认同这种此地无银的做法。
8. 集中力量办大事
论文除了各种「炫技」,还特别用了三页把所有为GPT-4不同系统有贡献人员都列出来,粗略估计应该已经超过百人,再次体现OpenAI内部团队成员众志成城、高度协作的状态。以此对比其他几家的团队作战能力,在众志成城这方面是不是差得有点远?
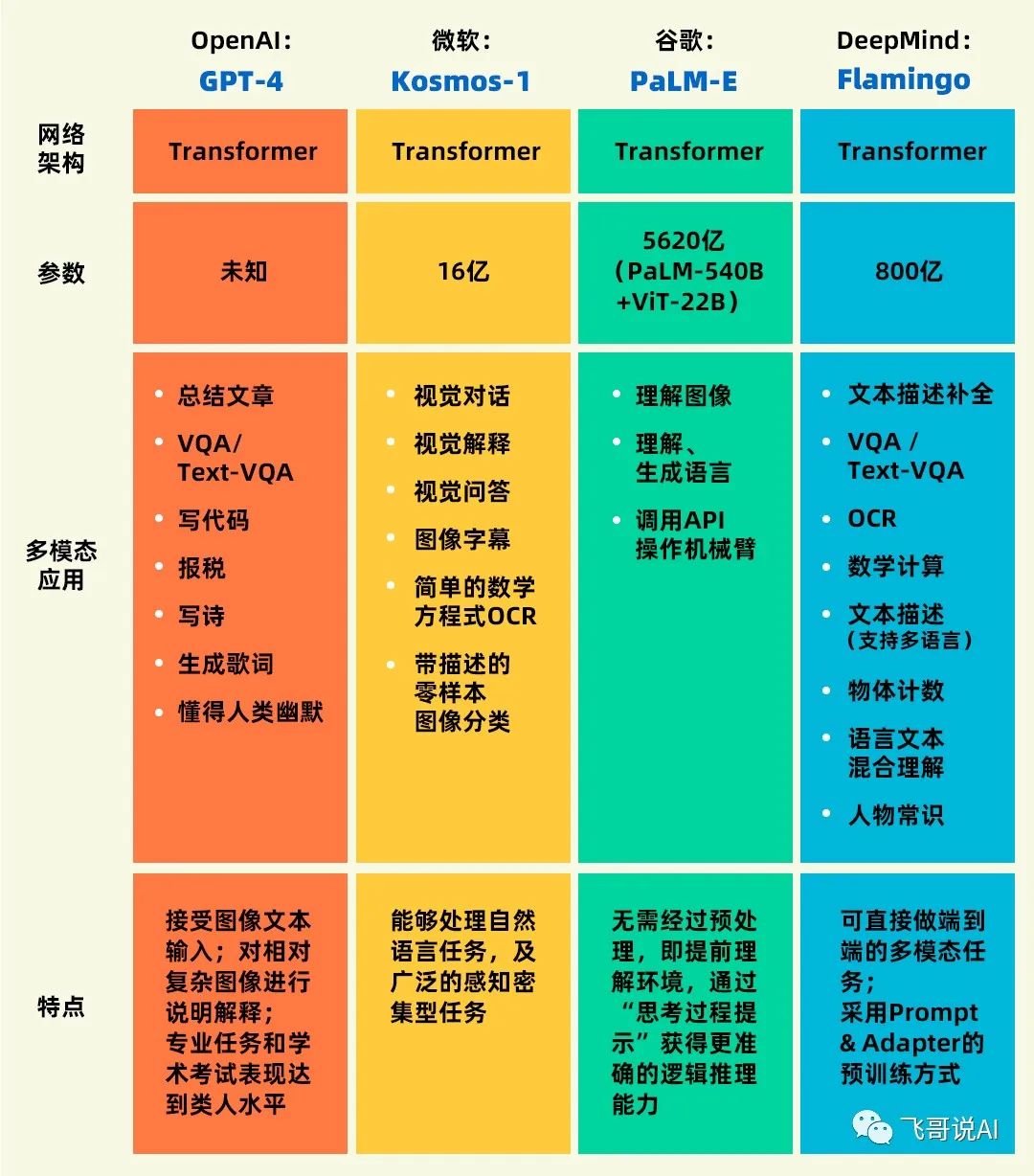
目前多模态大模型已经成为整个AI大模型发展的趋势和重要方向,而在这场大模型AI「军备竞赛」中,谷歌、微软、DeepMind等科技巨头都积极推出多模态大模型(MLLM)或大模型(LLM)。
开启新一轮军备竞赛:多模态大模型
微软:Kosmos-1
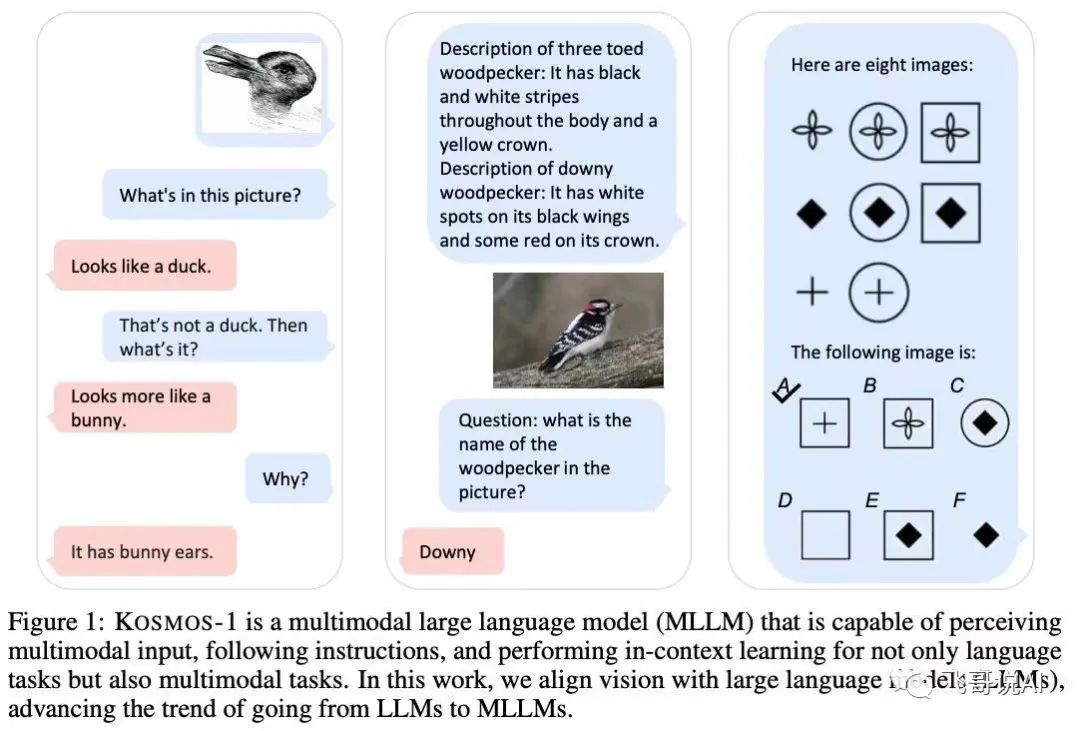
微软在3月初发布拥有16亿参数的多模态模型 Kosmos-1,网络结构基于 Transformer 的因果语言模型。其中,Transformer 解码器用作多模态输入的通用接口。
除了各种自然语言任务,Kosmos-1 模型能够原生处理广泛的感知密集型任务,如视觉对话、视觉解释、视觉问答、图像字幕、简单的数学方程式、OCR 和带描述的零样本图像分类。
谷歌:PaLM-E
3月初,谷歌和柏林工业大学的研究团队推出目前最大的视觉语言模型——PaLM-E,参数量高达5620亿(PaLM-540B+ViT-22B)。
PaLM-E是一个仅有解码器的大模型,在给定前缀(prefix)或提示(prompt)下,能够以自回归方式生成文本补全。模型通过加一个编码器,模型可以将图像或感知数据编码为一系列与语言标记大小相同的向量,将此作为输入用于下一个token预测,进行端到端训练。
DeepMind:Flamingo
DeepMind在去年4月推出Flamingo视觉语言模型,模型将图像、视频和文本作为提示(prompt),输出相关语言,只需要少量的特定例子既能解决很多问题,无需额外训练。
通过交叉输入图片(视频)和文本的方式训练模型,使模型具有 few-shot 的多模态序列推理能力,完成「文本描述补全、VQA / Text-VQA」等多种任务。
目前,多模态大模型已显示更多应用可能性,除了相对成熟的文生图外,人机互动、机器人控制、图片搜索、语音生成等大量应用逐一出现。
综合来看,GPT-4不会是AGI,但多模态大模型已经是一个清晰且确定的发展方向。建立统一的、跨场景、多任务的多模态基础模型会成为人工智能发展的主流趋势之一。
雨果说「科学到了最后阶段,便遇上了想象」,多模态大模型的未来或许正超越人类的想象。
文章版权声明
1 原创文章作者:7480,如若转载,请注明出处: https://www.52hwl.com/69233.html
2 温馨提示:软件侵权请联系469472785#qq.com(三天内删除相关链接)资源失效请留言反馈
3 下载提示:如遇蓝奏云无法访问,请修改lanzous(把s修改成x)
4 免责声明:本站为个人博客,所有软件信息均来自网络 修改版软件,加群广告提示为修改者自留,非本站信息,注意鉴别
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫