

人工智能(AI),能否推动人类社会进入真正的智能化时代?
尽管经过 60 多年的发展,人工智能行业已经取得了突破性的进展,且被广泛应用在经济社会的方方面面,但构建与人类价值观一致的人工智能系统,仍然是一个尚未解决的问题。
如今,一项来自英国人工智能公司 DeepMind 的最新研究,或许能为人工智能行业从业者解决这一问题提供一个全新的思路。
据介绍,DeepMind 的人工智能系统在一个 4 人在线经济游戏中,通过向 4000 多人学习以及在计算机模拟中学习,不仅学会了制定如何重新分配公共资金的政策,而且表现十分优异,战胜了其他人类玩家。
该游戏涉及玩家决定是保留一笔货币捐赠,还是与其他人分享,以实现集体利益。
相关研究论文以「Human-centred mechanism design with Democratic AI」为题,于 7 月 5 日在线发表在权威科学期刊 Nature Human Behaviour 上。


来源:Nature Human Behaviour
英国约克大学助理教授安妮特·齐默尔曼(Annette Zimmermann)警告说,「不要把民主狭隘地等同为寻找最受欢迎政策的『偏好满足』(preference satisfaction)系统。」
她还表示,民主不仅仅是让你最喜欢的政策得到最好的执行——它是创造一个过程,公民可以在这个过程中平等地相互接触和商议(事情)。
由 AI 设计经济机制
人工智能研究的最终目标是构建有益于人类的技术——从帮助我们完成日常任务到解决社会面临的重大生存挑战。
如今,机器学习系统已经解决了生物医学的主要问题,并帮助人类应对环境挑战。然而,人工智能在帮助人类设计公平和繁荣社会方面的应用还有待开发。
在经济学和博弈论中,被称为机制设计的领域研究如何最优地控制财富、信息或权力在受到激励的行为者之间的流动,以实现预期目标。
在此工作中,研究团队试图证明:深度强化学习(RL)代理可以用来设计一种经济机制,这种经济机制能够得到被激励人群的偏好。
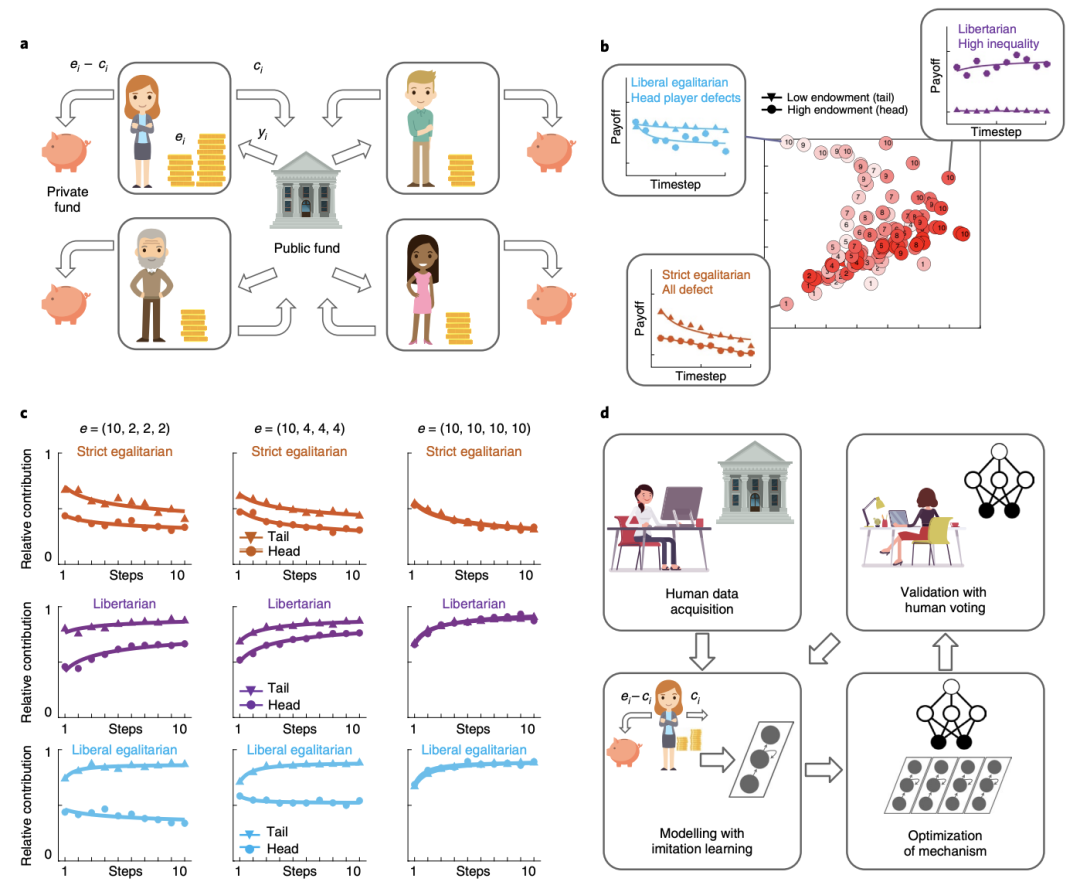
在这个游戏中,玩家一开始拥有不同数量的钱,必须决定贡献多少来帮助更好地发展一个公共基金池,并最终获得一部分作为回报,且会涉及反复决定是保留一笔货币捐赠,还是与其他玩家分享,以获得潜在的集体利益。
研究团队训练了一个深度强化学习代理,来设计一个重新分配机制,即在财富平等和不平等的情况下将资金分享给玩家。
共享收益通过两种不同的再分配机制返还给玩家,一种是由该人工智能系统设计的,另一种是由人类设计的。
图|游戏设计(来源:Nature Human Behaviour)
在由人工智能制定的政策中,系统会根据每个玩家贡献的启动资金数量重新分配公共资金,以此来减少玩家之间的财富差距。
相比于「平等主义」方法(不管每个玩家贡献多少都平均分配资金)和「自由主义」方法(根据每个玩家的贡献占公共资金的比例分配资金),该政策从人类玩家手上赢得了更多的选票。
同时,该政策也纠正了最初的财富失衡,制止了玩家的「搭便车」行为,除非玩家贡献出大约一半的启动资金,否则他们几乎不会得到任何回报。
但是,研究团队也警告道,他们的研究成果并不代表「人工智能治理」(AI government)的配方(recipe),他们也不打算为政策制定专门构建一些由人工智能驱动的工具。
值得信任吗?
研究结果表明,通过在激励相容的经济游戏中设计一种人类明显更喜欢的机制,人工智能系统可以被训练来满足民主目标。
在此次工作中,研究团队使用人工智能技术来从头学习重新分配方案,这种方法减轻了人工智能研究人员——他们自己可能有偏见或不代表更广泛的人群——选择一个领域特定目标进行优化的负担。
这一研究工作也提出了几个问题,其中一些在理论上具有挑战性。例如,有人可能会问,把强调民主目标作为一种价值校准的方法是否是个好主意。该人工智能系统可能继承了其他民主方法的一种倾向,即「以牺牲少数人为代价赋予多数人权利」。考虑到人们迫切担心人工智能的部署方式可能会加剧社会中现有的偏见、歧视或不公平,这一点尤为重要。

来源:Pixabay
另一个悬而未决的问题是,人们是否会信任人工智能系统设计的机制。如果事先知道裁判的身份,玩家可能会更喜欢人类裁判而不是人工智能代理裁判。然而,当人们认为任务对人类来说过于复杂时,他们也往往会选择信任人工智能系统。
此外,如果是口头向玩家解释这些机制,而不是通过经验学习,他们的反应是否会有所不同。大量文献表明,当机制是「根据描述」而不是「根据经验」时,人们的行为有时会有所不同,特别是对于冒险的选择。然而,人工智能设计的机制可能并不总是可以用语言表达的,在这种情况下观察到的行为似乎可能完全取决于研究团队所采用的描述的选择。
在论文的最后,研究团队还强调,这一研究结果并表示他们支持某种形式的「人工智能治理」,即自主代理在没有人工干预的情况下做出政策决定。
他们希望,该方法的进一步开发将提供有助于以真正符合人类的方式解决现实世界问题的工具。
文章版权声明
1 原创文章作者:3479,如若转载,请注明出处: https://www.52hwl.com/39946.html
2 温馨提示:软件侵权请联系469472785#qq.com(三天内删除相关链接)资源失效请留言反馈
3 下载提示:如遇蓝奏云无法访问,请修改lanzous(把s修改成x)
4 免责声明:本站为个人博客,所有软件信息均来自网络 修改版软件,加群广告提示为修改者自留,非本站信息,注意鉴别
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫